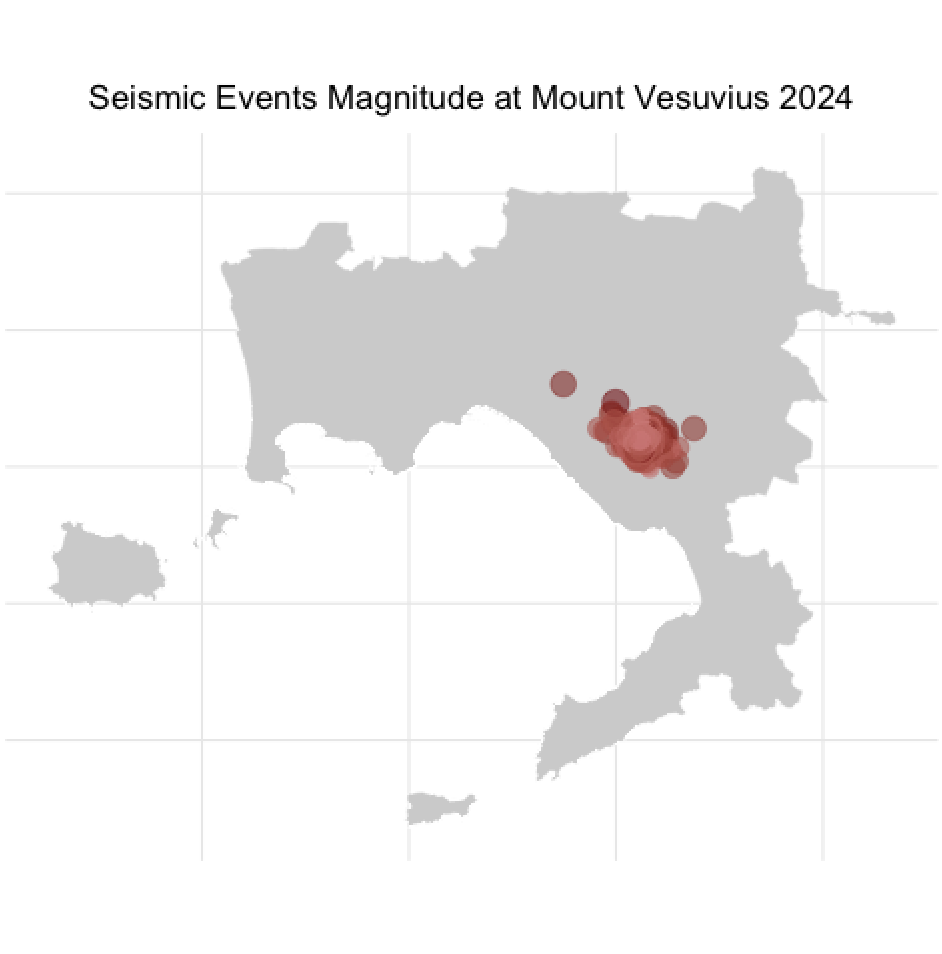
TyT2025W19: Seismic Events at Mount Vesuvius
The dataset this week explores seismic events detected at the famous Mount Vesuvius in Italy. It comes from the Italian Istituto Nazionale di Geofisica e Vulcanologia (INGV)’s Data Portal and can be explored along with other seismic areas on the GOSSIP website. The raw data was saved as individual CSV files from the GOSSIP website and some values were translated from Italian to English.