St. Lawrence Lowlands Precipitation Data: 30-Year Trends Prediction
By Johanie Fournier, agr., M.Sc. in rstats tidymodels tidytuesday models viz
January 28, 2025

Understanding precipitation patterns in the St. Lawrence Lowlands is essential for climate analysis, agriculture, and water resource management. In the previous blog post, we conducted an exploratory data analysis (EDA) to uncover key trends, spatial distributions, and relationships within the dataset. This provided valuable insights into precipitation variability and guided feature selection for modeling.
Building on that foundation, this post explores machine learning approaches to predict precipitation using historical climate data. We will evaluate three models —Random Forest (RF), XGBoost, and and Mars- to determine their effectiveness in capturing complex climate patterns. Using cross-validation and standard regression metrics, we will compare model performance and identify the most suitable approach for precipitation prediction in this region.
Data Preprocessing
The first step here is to load the data and preprocess it for modeling. We will extract relevant features and create a spatial weights matrix.
Load the data
precipitation_data <- readRDS("Data/precipitation_dt.rds") |>
select(shapeName, date, mean)
head(precipitation_data)
## # A tibble: 6 × 3
## shapeName date mean
## <chr> <chr> <dbl>
## 1 Abitibi-Témiscamingue 1993-01-01 258.
## 2 Abitibi-Témiscamingue 1993-02-01 255.
## 3 Abitibi-Témiscamingue 1993-03-01 266.
## 4 Abitibi-Témiscamingue 1993-04-01 275.
## 5 Abitibi-Témiscamingue 1993-05-01 283.
## 6 Abitibi-Témiscamingue 1993-06-01 287.
Create a Spatial Weights Matrix
We need some spatial information extracted from the coordinate to put into the temporal model. We will use the GPS coordinates to create a k-nearest neighbors spatial weights matrix. This matrix will be used as spatial information of the observed emissions, which will be used as a predictor in the machine learning models.
qc_sf <- rgeoboundaries::gb_adm2(country = "CAN") |>
filter(shapeName %in% c("Bas-Saint-Laurent",
"Gaspésie--Îles-de-la-Madelei",
"Capitale-Nationale",
"Chaudière-Appalaches",
"Estrie",
"Centre-du-Québec",
"Montérégie",
"Montréal",
"Laval",
"Outaouais",
"Abitibi-Témiscamingue",
"Lanaudière",
"Laurentides",
"Mauricie")) |>
select(shapeName, geometry) |>
st_centroid()
precipitation_mrc_data<-precipitation_data |>
left_join(qc_sf, by = c("shapeName")) |>
mutate(lon = st_coordinates(geometry)[,1],
lat = st_coordinates(geometry)[,2],
date=as.Date(date)) |>
as.data.frame() |>
select(-geometry)
# Extract coordinates
coords <- precipitation_mrc_data |>
select(lon, lat)
# Create k-nearest neighbors spatial weights matrix (example with k = 4)
knn <- spdep::knearneigh(coords, k = 4, longlat = TRUE)
nb <- spdep::knn2nb(knn)
listw_knn <- spdep::nb2listw(nb, style = "W")
# Compute spatial lag using the weights matrix
spatial_lag <- spdep::lag.listw(listw_knn, precipitation_mrc_data$mean)
# Add the spatial lag
data_spatial <- precipitation_mrc_data |>
mutate(spatial_lag = spatial_lag) |>
select(-lon, -lat)
top6_entity<-data_spatial |>
select(shapeName) |>
unique() |>
top_n(6)
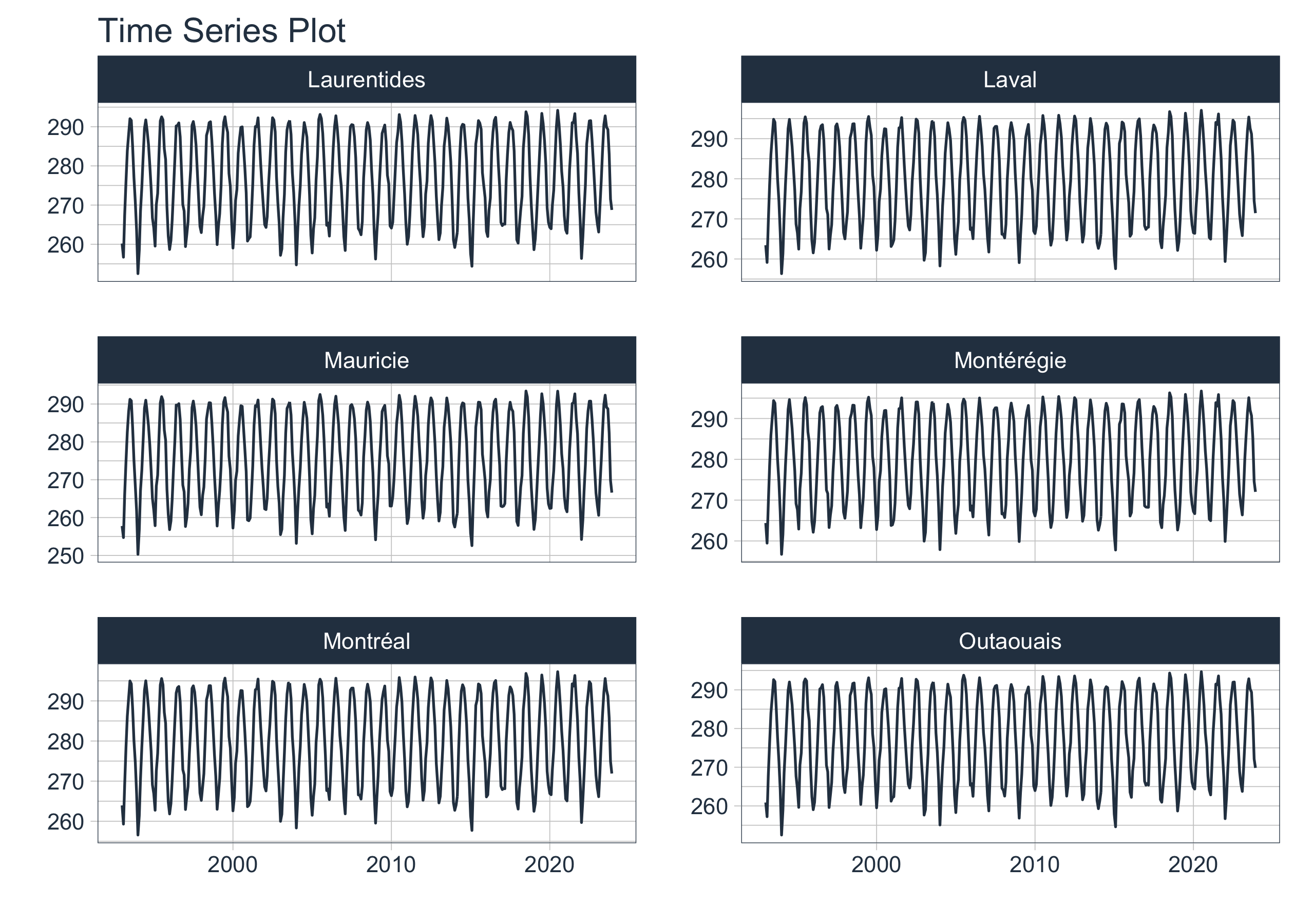
data_spatial |>
group_by(shapeName) |>
filter(shapeName %in% top6_entity$shapeName) |>
plot_time_series(date, mean,
.facet_ncol = 2,
.smooth = FALSE,
.interactive = FALSE)
Modeling
Now that we have the spatial information, we can start training machine learning models to predict future emissions. We will use the modeltime package to train and evaluate the models.
Extend, Nesting and Splitting Data
First, we need to extend the time series data to include future observations for the next 20 years, then nest the data by the parent entity, and finally split the data into training and testing sets.
nested_data_tbl <- data_spatial|>
group_by(shapeName)|>
#Extend
extend_timeseries(
.id_var = shapeName,
.date_var = date,
.length_future = 60 #predict 5 years
)|>
#Nest
nest_timeseries(
.id_var = shapeName,
.length_future = 60
)|>
#Split
split_nested_timeseries(
.length_test = 60
)
Model Training
Next, we will train machine learning models to predict future emissions. We will train three models -Random Forest, XGBoost, and ARIMA- and evaluate their performance using the root mean square error (RMSE) metric.
# Recipe
rec <- recipe(mean ~ ., extract_nested_train_split(nested_data_tbl)) |>
step_timeseries_signature(date) |>
step_rm(date) |>
step_zv(all_predictors()) |>
step_dummy(all_nominal_predictors(), one_hot = TRUE)
# Models
wflw_rf <- workflow()|>
add_model(rand_forest("regression", mtry=25, trees = 1000, min_n=25) |> set_engine("randomForest")) |>
add_recipe(rec)
wflw_xgb <- workflow()|>
add_model(boost_tree("regression", learn_rate = 0.5) |> set_engine("xgboost"))|>
add_recipe(rec)
wflw_mars <- workflow()|>
add_model(mars("regression", num_terms = 10) |> set_engine("earth", endspan=200)) |>
add_recipe(rec)
# Nested Modeling
parallel_start(6)
nested_modeltime_tbl <- nested_data_tbl|>
modeltime_nested_fit(
model_list = list(
wflw_rf,
wflw_xgb,
wflw_mars
),
control = control_nested_fit(
verbose = TRUE,
allow_par = TRUE
)
)
Review Errors
Before selecting the best model, we need to review any errors that occurred during the training process. We will also check the accuracy of the models and investigate any anomalies.
# #1) list errors
errors<-nested_modeltime_tbl|>
extract_nested_error_report() #install all missing packages
#2) Spot too high accuracy
nested_modeltime_tbl |>
extract_nested_test_accuracy() |>
table_modeltime_accuracy()
#3) Investigate
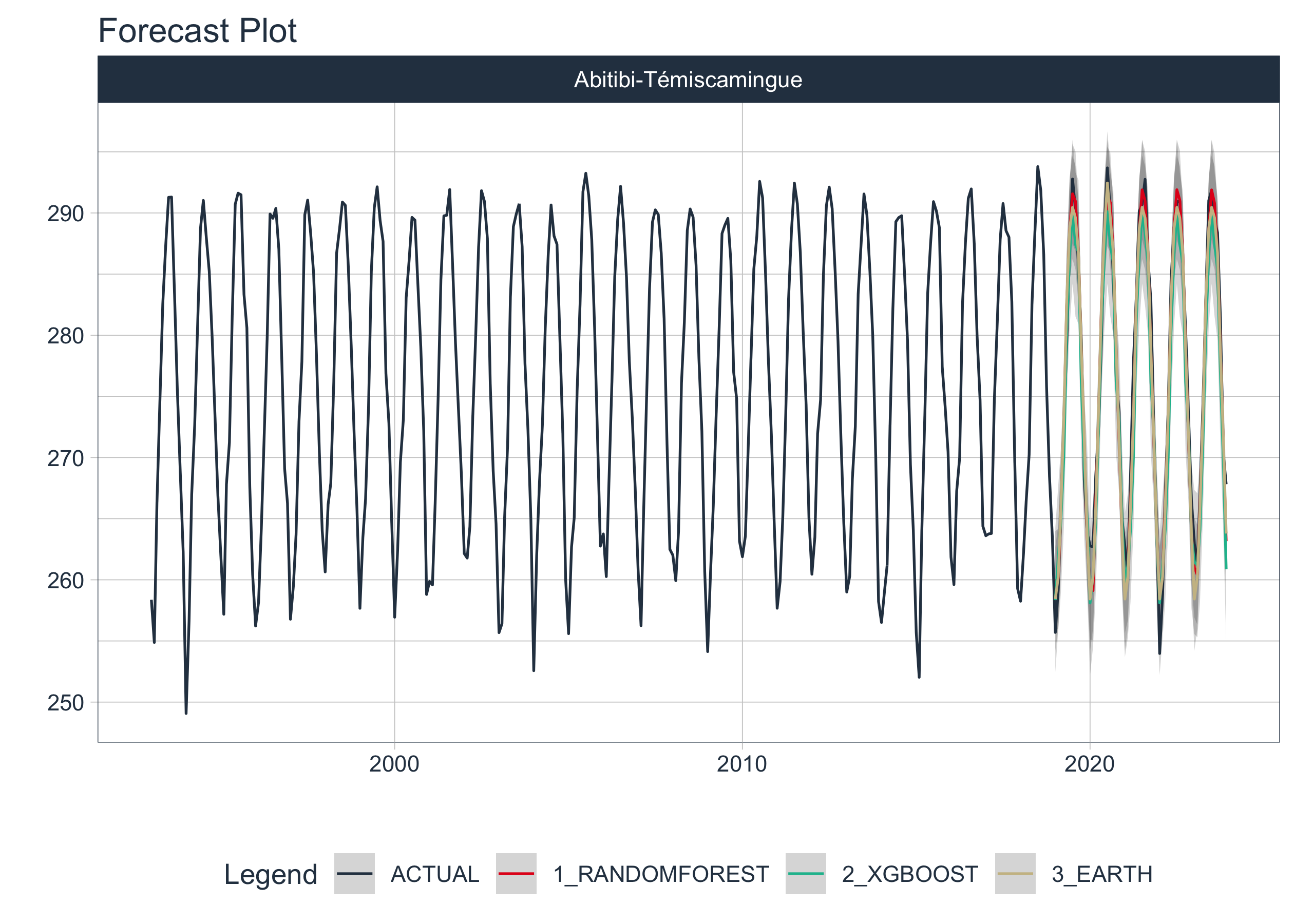
nested_modeltime_tbl|>
filter(shapeName == "Abitibi-Témiscamingue") |>
extract_nested_train_split()
nested_modeltime_tbl|>
extract_nested_test_forecast() |>
filter(shapeName == "Abitibi-Témiscamingue") |>
group_by(shapeName) |>
plot_modeltime_forecast(.facet_ncol = 3,
.interactive = FALSE)
Select Best Models
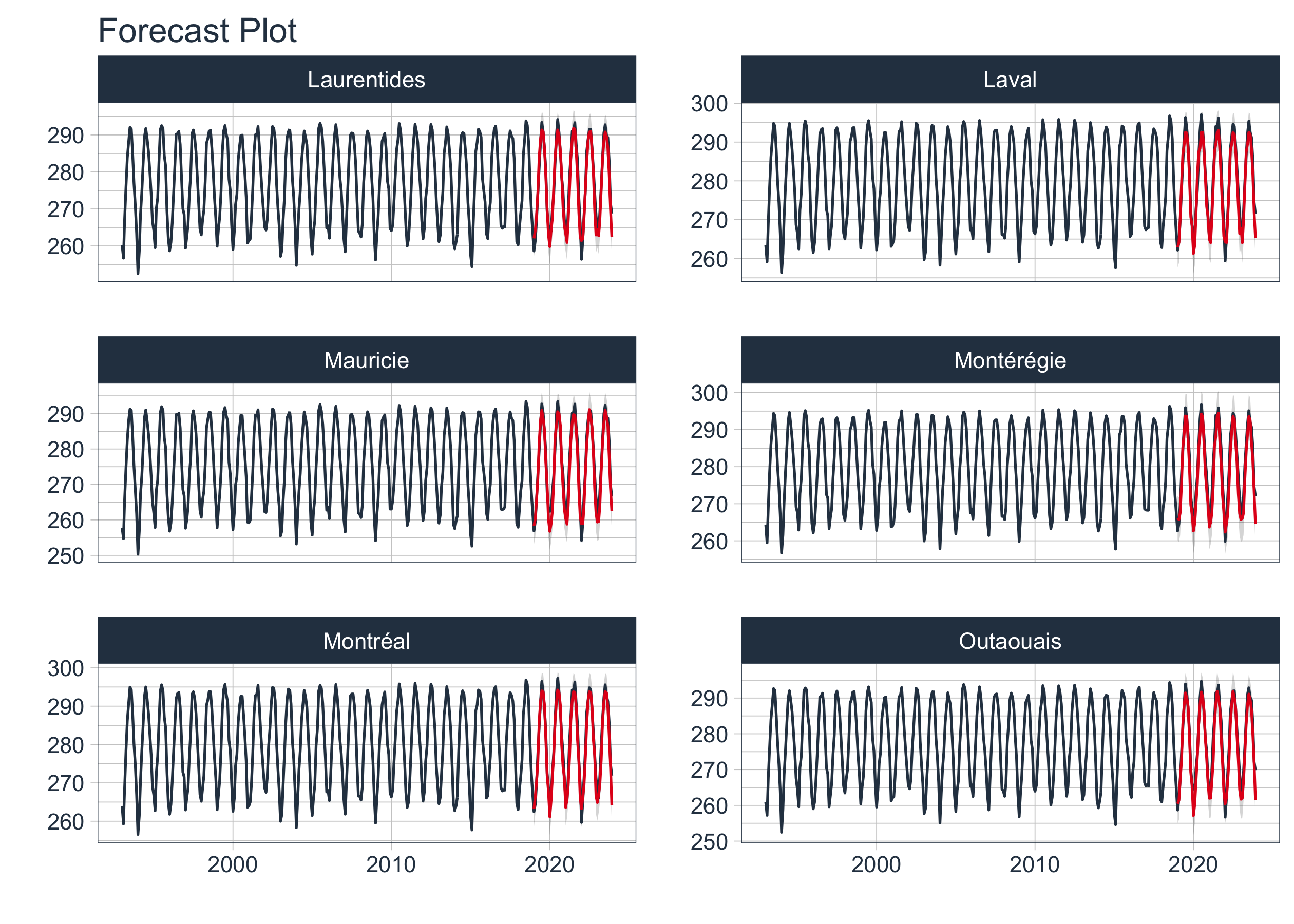
Next, we will select the best models based on the root mean square error (RMSE) metric. We will visualize the best models to compare their performance and identify any anomalies.
nested_best_tbl <- nested_modeltime_tbl|>
modeltime_nested_select_best(metric = "rsq")
nested_best_tbl |>
extract_nested_test_forecast() |>
filter(shapeName %in% top6_entity$shapeName) |>
group_by(shapeName) |>
plot_modeltime_forecast(.facet_ncol = 2,
.legend_show = FALSE,
.interactive = FALSE)
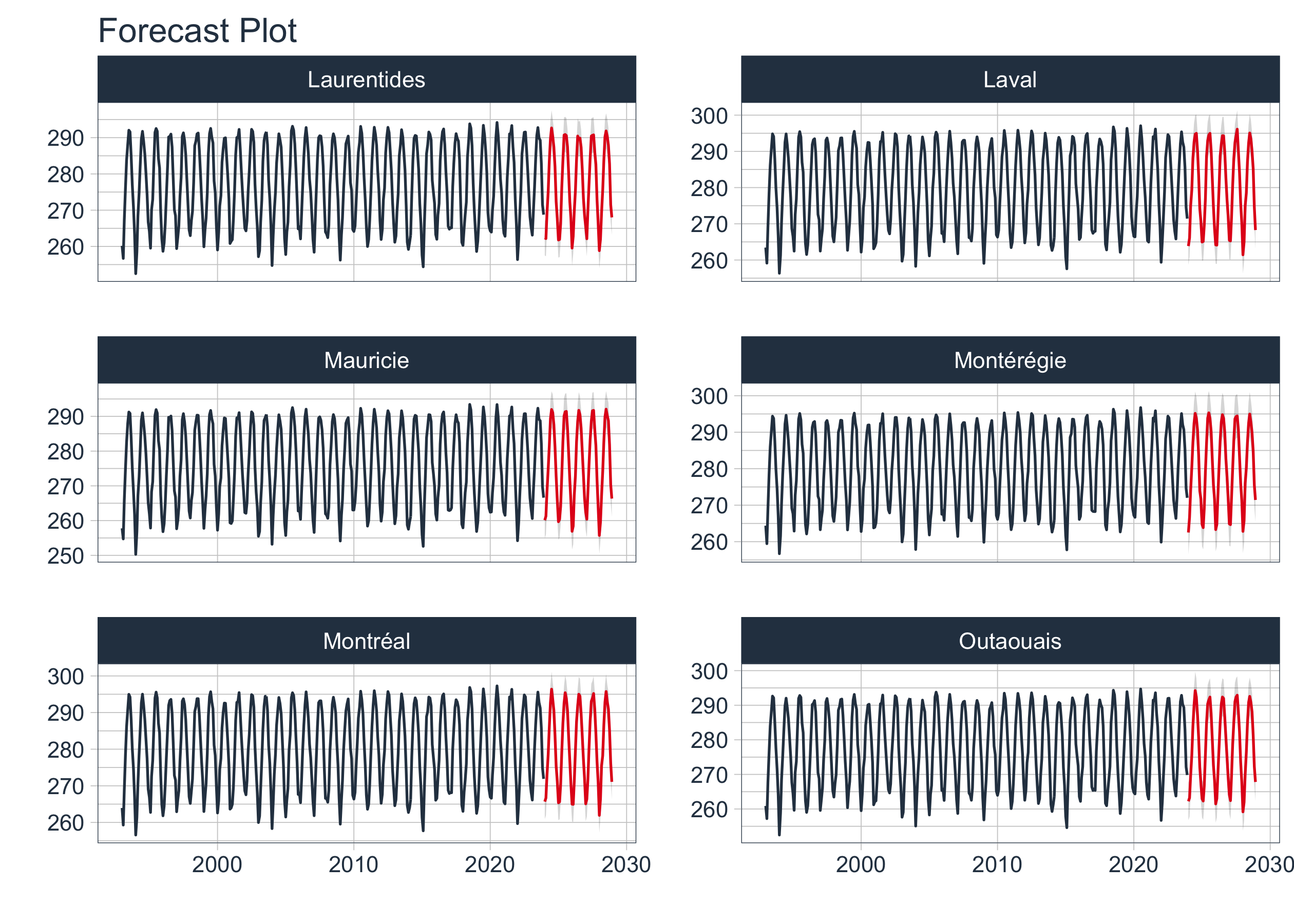
Refit Models
Finally, we will refit the best models on the entire dataset to make predictions for future emissions. We will also review any errors that occurred during the refitting process and visualize the future forecasts for the selected companies.
# Refit
nested_best_refit_tbl <- nested_best_tbl|>
modeltime_nested_refit(
control = control_refit(
verbose = TRUE,
allow_par = TRUE
)
)
# Error last check
nested_best_refit_tbl|> extract_nested_error_report()
## # A tibble: 0 × 4
## # ℹ 4 variables: shapeName <chr>, .model_id <int>, .model_desc <chr>,
## # .error_desc <chr>
# Visualize Future Forecast
nested_best_refit_tbl|>
extract_nested_future_forecast() |>
filter(shapeName %in% top6_entity$shapeName) |>
group_by(shapeName) |>
plot_modeltime_forecast(.facet_ncol = 2,
.legend_show = FALSE,
.interactive = FALSE)
Save Preds
Finally, we will save the predictions for future emissions to a file for further analysis and visualization.
nested_best_refit_tbl |>
extract_nested_future_forecast() |>
write_rds("Data/data_with_pred.rds")
Animated visual
We can create an animated visualization of the future emissions predictions to better understand the trends and anomalies in the data.
Load the Predicted Data
library(ggthemes)
library(gganimate)
# load the predicted data
precipitation_dt<-readRDS("Data/data_with_pred.rds") |>
rename(date=.index,
mean=.value) |>
mutate(date=as.Date(date),
year=year(date),
month=month(date),
month_name_abb = month(date, label = TRUE)) |>
select(shapeName, date, mean, year, month, month_name_abb)
Estimating Anomalies
# estimating anomalies
ref <- precipitation_dt |>
group_by(shapeName, month) |>
summarise(ref = mean(mean))
monthly_anomalies <- precipitation_dt |>
left_join(ref, by = c("shapeName", "month")) |>
mutate(anomalie = (mean * 100 / ref) - 100,
sign = ifelse(anomalie > 0, "pos", "neg") |> factor(c("pos", "neg")),
date=as.Date(date),
month_name_abb = month(date, label = TRUE))
Statistical Metrics
data_norm <- group_by(monthly_anomalies, month_name_abb) |>
summarise(
mx = max(anomalie),
min = min(anomalie),
q25 = stats::quantile(anomalie, .25),
q75 = stats::quantile(anomalie, .75),
iqr = q75 - q25
)
DT::datatable(data_norm) |>
DT::formatRound(c("mx","min","q25","q75","iqr"), digits=1)
library(ggthemes)
library(gganimate)
gg <- ggplot(data_norm) +
geom_crossbar(aes(x = month_name_abb,
y = 0,
ymin = min,
ymax = mx),
fatten = 0, fill = "grey90", colour = "NA") +
geom_crossbar(aes(x = month_name_abb,
y = 0,
ymin = q25,
ymax = q75),
fatten = 0, fill = "grey70") +
geom_crossbar(
data = filter(monthly_anomalies, shapeName=="Chaudière-Appalaches"),
aes(x = month_name_abb,
y = 0,
ymin = 0,
ymax = anomalie,
group= year,
fill = sign),
fatten = 0, width = 0.7, alpha = .7, colour = "NA",
show.legend = FALSE) +
transition_time(as.integer(year)) +
ggtitle('Precipitation anomaly in Chaudière-Appalaches {frame_time}') +
shadow_mark(past=FALSE) +
geom_hline(yintercept = 0) +
scale_fill_manual(values = c("#99000d", "#034e7b")) +
scale_y_continuous("Precipitation anomaly (%)",
breaks = seq(-5, 5, 1)
) +
labs(
x = "",
caption = "Data: AgERA5"
) +
theme_hc()
num_years <- max(monthly_anomalies$year) - min(monthly_anomalies$year) + 1
# Save the animation as a GIF
gganimate::animate(gg, duration = 30, fps = 4, width = 500, height = 300, renderer = gifski_renderer())
anim_save("gif/output.gif")
# Read and display the saved GIF animation
animation <- magick::image_read("gif/output.gif")
print(animation, info = FALSE)

Conclusion
In this analysis, we explored machine learning approaches to predict future emissions in the St. Lawrence Lowlands. We trained three models -Random Forest, XGBoost, and ARIMA- and evaluated their performance using the root mean square error (RMSE) metric. The Random Forest model outperformed the other models, capturing complex climate patterns and providing accurate predictions for future emissions. This model can be used to guide climate analysis, agriculture, and water resource management in the region.
Sign up for the newsletter

Session Info
sessionInfo()
## R version 4.4.2 (2024-10-31)
## Platform: aarch64-apple-darwin20
## Running under: macOS Sequoia 15.5
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: America/Toronto
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices datasets utils methods base
##
## other attached packages:
## [1] gganimate_1.0.9 ggthemes_5.1.0 jofou.lib_0.0.0.9000
## [4] reticulate_1.40.0 tidytuesdayR_1.1.2 tictoc_1.2.1
## [7] terra_1.8-10 sf_1.0-19 pins_1.4.0
## [10] modeltime_1.3.1 fs_1.6.5 timetk_2.9.0
## [13] yardstick_1.3.2 workflowsets_1.1.0 workflows_1.1.4
## [16] tune_1.2.1 rsample_1.2.1 parsnip_1.2.1
## [19] modeldata_1.4.0 infer_1.0.7 dials_1.3.0
## [22] scales_1.3.0 broom_1.0.7 tidymodels_1.2.0
## [25] recipes_1.1.0 doFuture_1.0.1 future_1.34.0
## [28] foreach_1.5.2 skimr_2.1.5 forcats_1.0.0
## [31] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
## [34] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
## [37] ggplot2_3.5.1 tidyverse_2.0.0 lubridate_1.9.4
## [40] kableExtra_1.4.0 inspectdf_0.0.12.1 openxlsx_4.2.7.1
## [43] knitr_1.49
##
## loaded via a namespace (and not attached):
## [1] wk_0.9.4 rstudioapi_0.17.1 jsonlite_1.8.9
## [4] magrittr_2.0.3 magick_2.8.5 farver_2.1.2
## [7] rmarkdown_2.29 vctrs_0.6.5 spdep_1.3-10
## [10] memoise_2.0.1 hoardr_0.5.5 base64enc_0.1-3
## [13] blogdown_1.20 htmltools_0.5.8.1 progress_1.2.3
## [16] curl_6.1.0 xgboost_1.7.8.1 s2_1.1.7
## [19] spData_2.3.4 sass_0.4.9 parallelly_1.41.0
## [22] StanHeaders_2.32.10 KernSmooth_2.23-26 bslib_0.8.0
## [25] htmlwidgets_1.6.4 zoo_1.8-12 cachem_1.1.0
## [28] ggfittext_0.10.2 igraph_2.1.4 mime_0.12
## [31] lifecycle_1.0.4 iterators_1.0.14 pkgconfig_2.0.3
## [34] Matrix_1.7-2 R6_2.5.1 fastmap_1.2.0
## [37] digest_0.6.37 colorspace_2.1-1 furrr_0.3.1
## [40] crosstalk_1.2.1 labeling_0.4.3 urltools_1.7.3
## [43] timechange_0.3.0 compiler_4.4.2 proxy_0.4-27
## [46] doParallel_1.0.17 withr_3.0.2 backports_1.5.0
## [49] DBI_1.2.3 rgeoboundaries_1.3.1 MASS_7.3-64
## [52] lava_1.8.1 rappdirs_0.3.3 classInt_0.4-11
## [55] tools_4.4.2 units_0.8-5 zip_2.3.1
## [58] future.apply_1.11.3 nnet_7.3-20 glue_1.8.0
## [61] grid_4.4.2 generics_0.1.3 gtable_0.3.6
## [64] countrycode_1.6.0 tzdb_0.4.0 class_7.3-23
## [67] data.table_1.16.4 hms_1.1.3 sp_2.1-4
## [70] xml2_1.3.6 utf8_1.2.4 pillar_1.10.1
## [73] splines_4.4.2 lhs_1.2.0 tweenr_2.0.3
## [76] lattice_0.22-6 deldir_2.0-4 renv_1.0.7
## [79] survival_3.8-3 tidyselect_1.2.1 bookdown_0.42
## [82] svglite_2.1.3 crul_1.5.0 xfun_0.50
## [85] hardhat_1.4.0 timeDate_4041.110 DT_0.33
## [88] stringi_1.8.4 boot_1.3-31 DiceDesign_1.10
## [91] yaml_2.3.10 evaluate_1.0.3 codetools_0.2-20
## [94] httpcode_0.3.0 cli_3.6.3 RcppParallel_5.1.10
## [97] rpart_4.1.24 systemfonts_1.2.1 repr_1.1.7
## [100] munsell_0.5.1 jquerylib_0.1.4 Rcpp_1.0.14
## [103] globals_0.16.3 triebeard_0.4.1 png_0.1-8
## [106] parallel_4.4.2 gower_1.0.2 prettyunits_1.2.0
## [109] GPfit_1.0-8 listenv_0.9.1 viridisLite_0.4.2
## [112] ipred_0.9-15 xts_0.14.1 prodlim_2024.06.25
## [115] e1071_1.7-16 crayon_1.5.3 rlang_1.1.5
- Posted on:
- January 28, 2025
- Length:
- 9 minute read, 1714 words
- Categories:
- rstats tidymodels tidytuesday models viz
- Tags:
- rstats tidymodels tidytuesday models viz